Setting up data analytics pipeline: the best practices
In a data science analogy with the automotive industry, the data plays the role of the raw-oil which is not yet ready for combustion. The data modeling phase is comparable with combustion in the engines and data preparation is the refinery process turning raw-oil to the fuel i.e., ready for combustion. In this analogy data analytics pipeline includes all the steps from extracting the oil up to combustion, driving and reaching to the destination (analogous to reach the business goals).
As you can imagine, the data (or oil in this analogy) goes through a various transformation and goes from one stage of the process to another. But the question is what is the best practice in terms of data format and tooling? Although there are many tools that make the best practice sometimes very use-case specific but generally JSON is the best practice for the data-format of communication or the lingua franca and Python is the best practice for orchestration, data preparation, analytics and live production
.
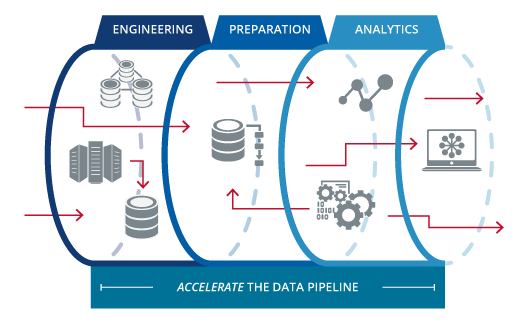
1 Datapipeline Architect Example
What is the common inefficiency and why it happens?
The current inefficiency is overusing of tabular (csv-like) data-formats for communication or lingua franca. I believe data scientists still overuse the structured data types for communication within data analytics pipeline because of standard data-frame-like data formats offered by major analytic tools such as Python and R. Data scientists start getting used to data-frame mentality forgetting the fact that tabular storage of the data is a low scale solution, not optimized for communication and when it comes to bigger sets of data or flexibility to add new fields to the data, data-frames and their tabular form are non-efficient.
DataOps Pipeline and Data Analytics
A very important aspect for analytics being ignored in some circumstances is going live and getting integrated with other systems. DataOps is about setting up a set of tools from capturing data, storing them up to analytics and integration, falling into an interdisciplinary realm of the DevOps, Data Engineering, Analytics and Software Engineering (Hereinafter I use data analytics pipeline and DataOps pipeline interchangeably.) The modeling part and probably some parts in data prep phases need a data-frame like data format but the rest of the pipeline is more efficient and robust if is JSON native. It allows adding/removing features easier and is a compact form for communication between modules. 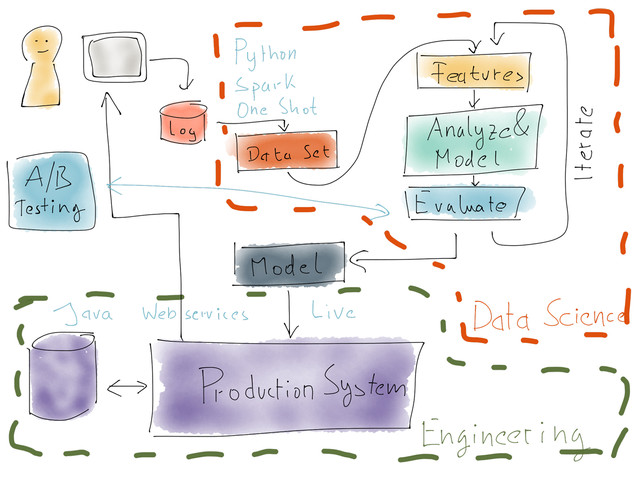 2
2
The role of Python
Python is a great programming language used not only by the scientific community but also the application developers. It is ready to be used as back-end and by combining it with Django you can build up full-stack web applications. Python has almost everything you need to set up a DataOps pipeline and is ready for integration and live production.
Python Example: transforming CSV to JSON and storing it in MongoDB
To show some capabilities of Python in combination with JSON, I have brought a simple example. In this example, a dataframe is converted to JSON (Python dictionaries) and is stored in MongoDB. MongoDB is an important database in today’s data storage as it is JSON native storing data in a document format bringing high flexibility .
### Loading packages
from pymongo import MongoClient import pandas as pd
# Connecting to the database
client = MongoClient('localhost', 27017)
# Creating database and schema
db = client.pymongo_test posts = db.posts
# Defining a dummy dataframe
df = pd.DataFrame({'col1': [1, 2], 'col2': [0.5, 0.75]}, index=['a', 'b'])
# Transforming dataframe to a dictionary (JSON)
dic=df.to_dict()
# Writing to the database
result = posts.insert_one(dic) print('One post: {0}'.format(result.inserted_id))The above example shows the ability of python in data transformation from dataframe to JSON and its ability to connect to various tooling (MongoDB in this example) in DataOps pipeline.
Recap
This article is an extension to my previous article on future of data science (https://bit.ly/2sz8EdM). In my earlier article, I have sketched the future of data science and have recommended data scientists to go towards full-stack. Once you have a full stack and various layers for DataOps / data analytics JSON is the lingua franca between modules bringing robustness and flexibility for this communication and Python is the orchestrator of various tools and techniques in this pipeline.
1: The picture is courtesy of https://cdn-images-1.medium.com/max/1600/1*8-NNHZhRVb5EPHK5iin92Q.png 2: The picture is courtesy of https://zalando-jobsite.cdn.prismic.io/zalando-jobsite/2ed778169b702ca83c2505ceb65424d748351109_image_5-0d8e25c02668e476dd491d457f605d89.jpg
